
Exploring the Quality of the Digital Historical Newspaper Archive KubHist
Exploring the Quality of the Digital Historical Newspaper Archive KubHist
Abstract
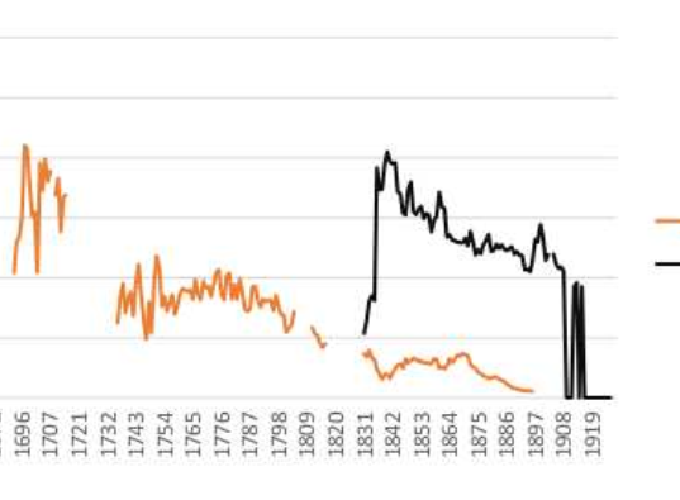
The KubHist Corpus is a massive corpus of Swedish historical newspapers, digitized by the Royal Swedish library, and available through the Språkbanken corpus infrastructure Korp. This paper contains a first overview of the KubHist corpus, exploring some of the difficulties with the data, such as OCR errors and spelling variation, and discussing possible paths for improving the quality and the searchability.
Type
Publication
In the Digital Humanities in the Nordic Countries 4th Conference, DHN2019
Date
March, 2019