The Strengths and Pitfalls of Large-Scale Text Mining for Literary Studies

The Strengths and Pitfalls of Large-Scale Text Mining for Literary Studies
Abstract
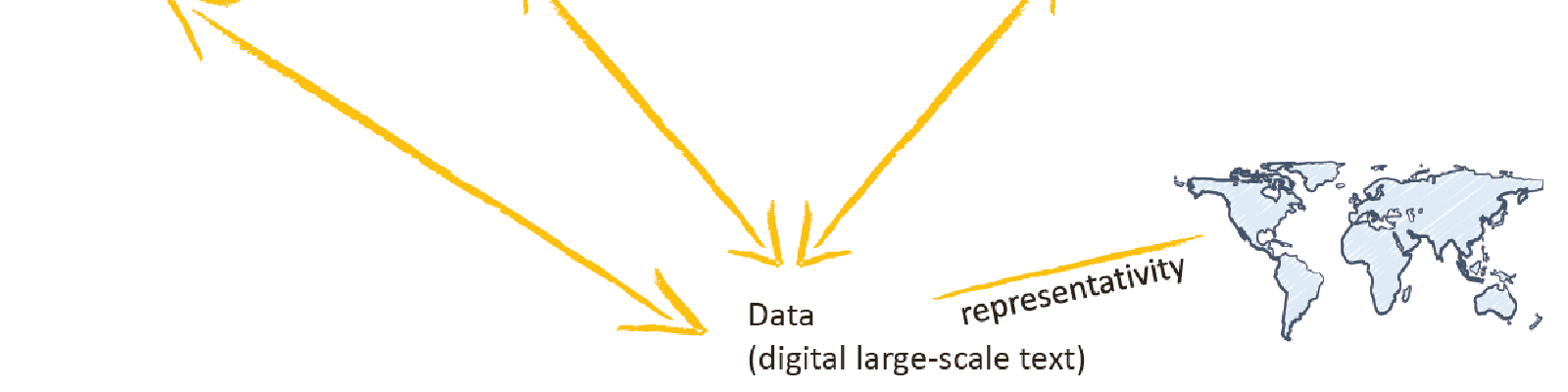
This paper is an overview of the opportunities and challenges of using large-scale text mining to answer research questions that stem from the humanities in general and literature specifically. In this paper, we will discuss a data-intensive research methodology and how different views of digital text affect answers to research questions. We will discuss results derived from text mining, how these results can be evaluated, and their relation to hypotheses and research questions. Finally, we will discuss some pitfalls of computational literary analysis and give some pointers as to how these can be avoided.
Type
Publication
In Samlaren, Volume 140, p.198–227
Date
March, 2020
Links
